什麼是 DeepSeek?
DeepSeek 是一家位於中國杭州的人工智慧初創公司,成立於 2023 年,由對沖基金幻方量化的創辦人梁文鋒經營。該公司的目標是開發出與 OpenAI 的 ChatGPT、Google 的 Gemini 等相媲美的人工智慧技術。
技術創新與產品

DeepSeek 推出了多個大型語言模型,其中最引人注目的是 DeepSeek-V3 和 DeepSeek-R1。這些模型採用了創新的架構,如 DeepSeekMoE(混合專家)和 DeepSeekMLA(多頭潛在注意力),使得訓練和推理過程更加高效,並顯著降低了計算資源的需求。
- DeepSeek-V3:這是一款大型語言模型,其訓練成本僅為 Llama 3 的 1%,推理成本則只有 OpenAI o1 的 3%。它在性能上已經可以與 GPT-4 等高端模型媲美,並且在開源模型中排名第一。
- DeepSeek-R1:這是一個專門設計用於協助開發者撰寫和優化程式碼的模型。它不僅能生成程式碼,還具備除錯功能,能夠分析程式碼的效率和潛在錯誤。
市場影響與反響
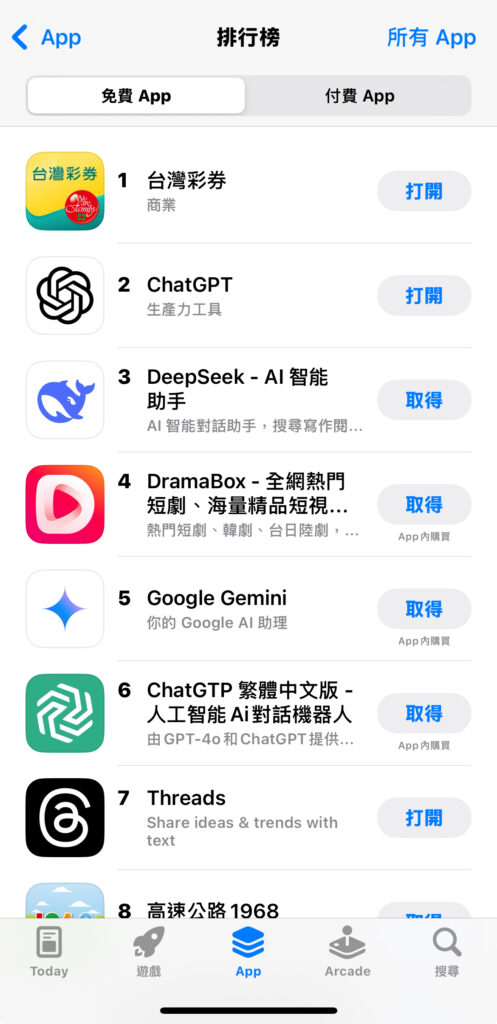
自從 2024 年 12 月 26 日推出以來,DeepSeek 的下載量迅速攀升,短短一週內便達到約 240 萬次,超越了 ChatGPT,成為市場焦點。其低訓練成本(約 560 萬美元)和相對較少的運算資源(僅使用約 2000片Nvidia 晶片)引發了業界的廣泛關注,挑戰了傳統對於高算力、高資本需求的認知。
DeepSeek 的成功不僅在於技術創新,也在於其開源策略,使得開發者能夠根據自身需求客製化和部署模型。這一模式可能會重新定義AI產業競爭規則,並為中國AI產業提供新的機遇。
DeepSeek 以其創新的技術架構、低成本運作及強大的模型性能,在全球 AI 市場中迅速崛起,挑戰了美國科技巨頭的主導地位。這不僅是一次技術革命,也預示著全球人工智慧領域競爭格局的變化。
DeepSeek 的主要技術創新有哪些?
DeepSeek的主要技術創新包括以下幾個方面:
混合專家(MoE)架構
DeepSeek 採用了混合專家模型(Mixture-of-Experts, MoE),這種架構允許模型在處理任務時僅啟動一部分參數。具體來說,DeepSeek 的 R1 模型擁有 6710 億個參數,但每次推理時只啟動約370億個參數,這樣的設計大幅提高了運算效率並降低了計算成本。
多頭潛在注意力(MLA)
DeepSeek-V3模型引入了多頭潛在注意力架構,通過將關鍵值映射至低維潛空間向量來提升長文本處理的效率。這一創新使得模型能夠更有效地處理大量資訊,特別是在需要長上下文的應用中。
強化學習技術
DeepSeek-R1在訓練過程中大規模應用了強化學習技術,這使得模型在僅有極少標註數據的情況下,仍能顯著提升推理能力。這種方法不僅降低了對大量標註數據的依賴,也減少了訓練成本。
高效的記憶體使用
DeepSeek 使用 FP8 混合精度訓練框架,相較於傳統的 FP16 和 FP32,FP8 能夠顯著減少記憶體的使用,從而提高訓練和推理的效率。此外,DeepSeek 還開發了 DualPipe 算法,以降低跨節點通訊資源消耗。
開源可訪問性
DeepSeek 以開源方式發布其模型,允許用戶自由下載、部署和自定義,這與許多競爭對手形成鮮明對比。開源策略不僅促進了社區參與,也使得開發者能夠根據自身需求進行調整和優化。
成本效益
DeepSeek 的整體設計和技術創新使其訓練成本大幅降低。R1 模型的開發成本僅為數百萬美元,相比之下,美國大型科技公司通常需要投入數億美元。這種經濟高效的方法使 DeepSeek 能夠提供高性能 AI 功能,同時保持競爭優勢。
總結來說,DeepSeek 透過上述技術創新,不僅提升了模型性能,同時也顯著降低了訓練和運行成本,使其在全球 AI 市場中迅速崛起。
DeepSeek 的性能如何與 OpenAI 的 ChatGPT 相比?

DeepSeek 與 OpenAI 的 ChatGPT 在性能上的比較顯示出兩者各自的優勢和特點,以下是主要的比較要點:
性能與準確性
- 數學與編程任務:DeepSeek 在數學問題上表現優異,達到 90% 的準確率,超過 ChatGPT 的 83%。在編程方面,DeepSeek 在邏輯謎題的除錯成功率達 97%,顯示其在技術任務上的專業能力。
- 推理能力:DeepSeek 利用強化學習進行後期訓練,以提高其推理能力,特別是在需要步驟解析的問題上表現良好。相對而言,ChatGPT 則更擅長解決複雜的多步問題。
架構與效率
- 模型架構:DeepSeek 使用混合專家(MoE)架構,雖然擁有 6710 億個參數,但每次推理僅啟動約 370 億個參數,這樣的設計使其能夠在計算效率上優於 ChatGPT。ChatGPT 則基於密集模型架構,對計算資源的需求較高。
- 訓練成本:DeepSeek 的訓練成本約為 558 萬美元,而 ChatGPT 的訓練成本則超過 1 億美元。這使得 DeepSeek 在成本效益上具有明顯優勢。
功能與應用場景
- 專業應用:DeepSeek 專注於技術性和專業性問題,如編程、數據分析等,並且能快速提供針對性的解決方案。相對而言,ChatGPT 則更為通用,適合內容創作、故事講述和日常互動等多種應用。
- 多模態支持:ChatGPT 支持文本和圖像輸入,並具備語音互動功能,使其在多樣化應用場景中更具靈活性,而 DeepSeek 目前主要限於文本查詢。
成本與可用性
- 免費使用:DeepSeek 完全免費且無查詢限制,而 ChatGPT 則需要支付費用才能使用其高級功能。這使得 DeepSeek 成為開發者和企業的一個吸引選擇。
- 開源特性:DeepSeek 是開源的,允許用戶根據自己的需求進行定制和部署,而 ChatGPT 則是封閉的商業產品,這限制了其可定制性。
總體來看,DeepSeek 在專業技術任務上表現出色且具成本效益,而 ChatGPT 則在多樣化應用和使用便利性上具有優勢。選擇哪一款工具取決於用戶的具體需求:如果需要一個高效、專注於技術解決方案的工具,DeepSeek 可能是更好的選擇;如果需要一個通用且易於使用的 AI 助手,則 ChatGPT 可能更為合適。
DeepSeek 對於敏感問題如何應對?

DeepSeek 在應對敏感問題方面的策略主要體現在以下幾個方面:
自我審查機制
DeepSeek 對於中國政府認為的敏感議題進行自我審查。報導指出,該平台會迴避涉及六四天安門事件、中國入侵台灣等地緣政治問題的詢問,這顯示出其在內容管理上的謹慎態度。
數據傳輸與隱私政策
DeepSeek 的政策明確表示,將大量用戶數據直接傳回中國,這引發了外界對個人資料安全的擔憂。美國海軍已經要求其成員不得下載 DeepSeek,因為這可能涉及潛在的安全和道德問題。義大利的個資保護機構也對 DeepSeek 提出了資料存放及使用目的的詢問,要求其在 20 天內作出回應。
限制公務機關使用
根據台灣數位發展部的指示,公務機關被明令禁止使用 DeepSeek,以避免機密資料或個人資訊被傳送至可能存在資安疑慮的產品上,這一措施反映了對於敏感訊息處理的高度警覺。
用戶反饋與實測結果
在實測中,有用戶發現 DeepSeek 在處理某些敏感問題時會出現「鬼打牆」的情況,即無法提供直接的回答,而是迴避問題或給出模糊的回應。這表明 DeepSeek 在面對敏感話題時,可能會選擇不直接回應,以符合相關法律和政策要求。
DeepSeek 在應對敏感問題上採取了自我審查、數據保護、限制特定用戶群體使用等多重策略,以降低法律和安全風險。然而,這也引發了外界對其數據處理透明度和用戶隱私保護的質疑。
DeepSeek 以其強大的技術創新、開源可訪問性和優異的成本效益,正逐步成為 AI 搜尋與對話領域的重要競爭者。雖然與 ChatGPT 在某些方面仍有差距,但其高效的架構設計和靈活的應用場景,使其成為值得關注的 AI 解決方案。隨著 AI 技術的不斷發展,DeepSeek 是否能真正顛覆市場?現在就來深入了解,探索它的潛力與未來發展!