讓 Gemini Omni 成爲你的「全能魔幻導演」
Google 最新發表的 Gemini Omni,最厲害的地方在於它不只是聽得懂話,而是它開始懂得我們真實世界的物理規則,讓你用聊天的方式就能直接拍影片、改影片。
我們可以把過去接觸過的 AI 影片生成想像成「抽盲盒」。當你輸入了一長串生硬的關鍵字,點下生成,接著就只能祈禱出來的畫面不要太奇怪。如果影片裡的人手捏得不對、背景光線很假,你通常拿它沒辦法,只能默默把整段指令刪掉,重新再抽一次盲盒。
但這次 Google 帶來的 Gemini Omni 完全不同。你可以把它想像成一位非常有默契、隨時待命的「助理導演」。你不再需要學會那些冷冰冰的程式碼或專業術語,只要用平常和朋友聊天說人話的方式跟它溝通,它就能幫你把腦海中的畫面做出來,甚至直接修改影片裡的某個小角落。這種互動方式,把原本高不可攀的技術門檻,變成每個人都能輕鬆上手的日常工具。
Gemini Omni 看懂世界的物理規則
以往只要打錯一個字,AI 影片就得全部重來。現在新模型解決了這個痛點,讓每一次的調整都能好好的黏在前一個畫面上。
很多人在嘗試 AI 生成影片時,最常遇到的挫折就是「畫面不夠自然」。例如:水杯倒了,水卻往天上飄;人走路的時候,影子跟腳步完全對不上。
Gemini Omni 這次的一大突破,在於它在訓練過程中融入了科學家所說的「世界模型(World Model)」概念。聽起來很玄,但換個角度看,其實就是這個 AI 在腦海裡模擬出了一個擁有重力、光影、甚至液體流動規律的虛擬世界。
當你在影片中放進一隻貓,它知道貓跳下來時應該有怎樣的重力下墜感;當你改變室內的燈光,它知道牆壁上的陰影應該跟著怎麼移動。因為懂了這些日常生活的物理規則,它做出來的影片就不會再給人一種生硬拼湊的虛假感,而是自然流暢許多。
不需要背指令!用「對話」就能精準修改局部畫面
另外一個讓很多人卡關的點,是「無法微調」。過去如果你覺得影片裡角色的衣服顏色不對,你可能得整部影片重新生成,而且重新生成的畫面往往和原本的長得完全不一樣。
Gemini Omni 引入了「連續對話修改(Conversational Editing)」的能力。也就是說,它能記住你前一秒生成的畫面。你可以直接對它說:「畫面很棒!但幫我把背景裡的那面鏡子變成流動的水,其他地方維持原狀喔。」它就能完美聽懂你的指令,只動鏡子,不動其他家具。這種像是在跟設計師來回討論的修改方式,才是真正能幫上忙的效率工具。
實測怎麼用?3 個融入工作與生活的實用情境
不要覺得這離我們很遠,實際上很多人已經開始嘗試在簡報、社群短影音上用它來幫忙省時間了。
情境一:做簡報不再找不到配圖,用文字和草圖直接生出動畫解說
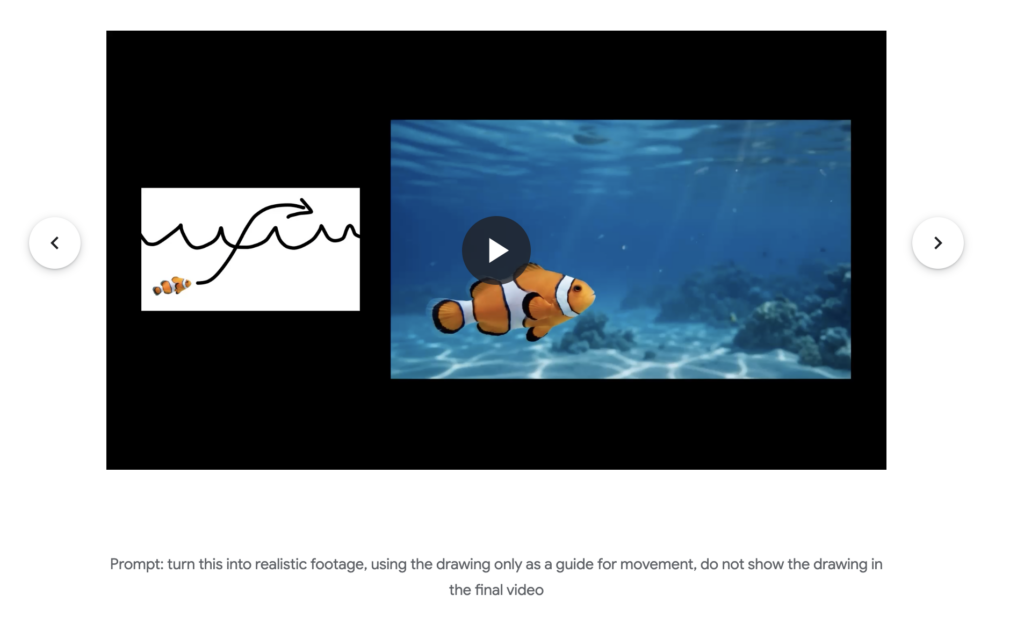
在工作上做簡報或商業提案時,我們經常需要一些概念插圖。上網到處找免費圖庫,不是風格不統一,就是得擔心版權問題。實際上很多人卡在這一步,最後只能放上密密麻麻的文字。
現在,你可以試著在紙上畫個簡單的線條草圖(例如:一個工廠的生產線流程),然後把這張草圖和你的簡報大綱一起餵給 Gemini Omni。它能根據你的草圖結構,直接幫你衍生出一段幾秒鐘、風格精緻的動畫解說影片。這不僅讓你的提案看起來更有說服力,也省去了大把在圖庫裡撈針的時間。
情境二:社群小編的福音,用日常對話就能把一段平淡影片變出魔幻畫風

如果你平時有在經營 IG Reels 或 YouTube Shorts,一定知道現在大家滑短影音的節奏非常快,前三秒如果抓不住眼球,內容做得再好都沒用。
有了這個工具,社群小編在戶外用手機隨手拍的一段普通街景短片,就能迎來全新轉機。你可以把影片上傳,然後對 Gemini Omni 說:「幫我把這段影片轉成 80 年代復古霓虹燈曲風的感覺」,或者是「把背景的建築物都變成日系動漫的畫風」。原本平淡無奇的素材,在幾秒鐘內就能多出好幾種風格變換,而且完全不需要動用到複雜的特效剪輯軟體。
情境三:不想露臉也能做影音?語音與虛擬分身的新嘗試
對於許多想嘗試做影音內容,但不好意思跟真人開口、或者因為個人隱私不想露臉的學習者來說,Gemini Omni 提供的個人化化身(Avatar)功能是一個很值得關注的方向。
它就像是一個永遠不會疲勞的數位替身,只要提供你的聲音素材和特定照片,它就能幫你合成出一段正在說話的虛擬影像。不過,說實話,官方目前基於安全與防範深偽(Deepfake)詐騙的考量,對這項功能的開放態度非常謹慎,現階段多用於特定的安全測試環境中,一般使用者可能還需要再等等。
想體驗先看這!Gemini Omni 的免費/付費使用限制
天底下沒有完全白吃的午餐,新技術雖然厲害,但在出發體驗前,我們得先搞懂它的免費版限制與付費門檻,才不會乘興而來卻卡在權限門口。
免費版可以用嗎?有哪些卡關的限制?
很多人看到新工具發表,最想知道的就是:「那我不用花錢可以用到什麼程度?」
說實話,目前 Google 對於這種最新、最消耗雲端算力的影片生成與對話修改功能,通常採取「擠牙膏式」的逐步放寬策略。如果你使用的是一般完全不付費的 Google 免費帳號,目前進到 Gemini 介面中,多半只能體驗到基礎的 Omni Flash 模型效能。這意味著它在回答你的文字問題、幫你修改文章或辨識圖片時速度非常快,但如果你想把手邊的一段大影片丟給它,叫它幫你直接進行「連續對話修改」或生成高畫質短片,免費版帳號通常會遇到排隊等待時間過長、或者是每日生成配額極低的硬性限制。
此外,從本週開始,使用者也能在 YouTube Shorts 和 YouTube Create 應用程式中免費體驗這項功能。
付費版就無限制嗎?進階用戶要注意的隱形門檻
那麼,如果每個月心甘情願拿出 20 美金,訂閱了 Google One AI Premium 方案,或者是使用 Pro/Ultra 等級的開發者用戶,就能毫無顧忌地暢玩了嗎?
實際上很多人卡在這一步。即使你付了費,現階段依然有三大隱形門檻需要注意:
- 高速配額限制(Speed Cap):付費版提供的是「高速生成額度」。當你在短時間內高頻率地叫 AI 幫你生影片、改畫面,一旦超過了當月的雲端算力配額,系統並不會讓你斷線,但會默默把你的優先順序往後調,讓你的生成速度變慢,或者暫時將模型降級。
- 影片長度限制:目前的 Gemini Omni 模型在處理影片時,核心強項在於精準的「短片片段(Clips)」修改與生成。你很難直接丟給它一部一小時的微電影叫它直接大改,目前多半還是以幾秒鐘到幾十秒的短影音素材為主。
- 區域與語言開放進度:部分最前沿的連續影片修改功能,通常會優先在英語系地區的測試版(Workspace Labs 或特定的開發者環境)上線,台灣使用者在繁體中文的介面上,有時候需要切換語系或者等待官方伺服器陸續佈署,才能完整體驗到全部功能。
4 個 Gemini Omni 的常見問題
如果你看到這裡覺得有些模糊,其實很正常。我們把大家最常問的問題整理在下面,幫你一次釐清。
Q1:一般人現在要在哪裡才能體驗到 Gemini Omni 的功能?
目前 Google 正在全球陸續開放相關權限。現階段擁有 Google One AI Premium 方案的訂閱用戶,或是透過 Google Flow、Google Cloud 平台使用 Pro 和 Ultra 等級模型的開發者,可以最快體驗到最新的 Omni 系列模型。一般使用者可以隨時留意自己 Gemini 網頁版或 App 的更新通知。
Q2:用這個生出來的影片,會不會有版權或是假新聞的安全問題?
這在產業共識上是非常受到重視的安全議題。Google 官方在發布時特別強調,為了防止技術被濫用,所有由 Gemini Omni 生成或經由其深度修改的影片內容,系統都會在後台自動加上不可見的 SynthID 數位浮水印。這種浮水印不會影響肉眼觀看,但未來的影音平台與辨識軟體可以藉此輕鬆判讀這是不是由 AI 做出來的畫面,藉此降低假訊息傳播的風險。
Q3:如果我付費版的高速配額用完了,我會被直接斷線不能使用嗎?
不會的。當付費用戶的高速算力配額用完時,Google 的常見做法是採取「降速不中斷」的策略。你的帳號依然可以使用服務,只是生成影片的等待時間會變長,或者系統會自動幫你切換到速度較快、但處理複雜畫面能力稍弱的 Flash 等級模型,你的日常創作節奏不會因此被強行中斷。
Q4:Gemini Omni 跟之前聽到的其他 AI 影片工具(如 OpenAI Sora)有什麼不一樣?
傳統的 AI 影片工具,多半擅長的是「從無到有(Text-to-Video)」的影片生成,你想改動畫面就得重新輸入一整段極其複雜的提示詞。而 Gemini Omni 最大的不同在於它的「多模態雙向溝通」與「連續對話修改」能力。它更擅長拿你現有的影片、圖片或草圖,透過像朋友般的一來一回對話來進行微調,兩者在實用場景上的定位不太一樣。
在未來的 AI 學習路上,我們不用強求自己在一夜之間變成科技專家。只要每天多弄懂一個工具能幫我們解決什麼生活小問題,你就已經走在對的學習路線上了。對於 Gemini Omni 的後續開放進度與實用小技巧,我們也會持續為大家追蹤更新,讓我們一起放輕鬆、跟著節奏慢慢往前走!
資料來源:https://blog.google/intl/zh-tw/products/explore-get-answers/gemini-omni/





