*本篇文章翻譯自 Tensor.Art Workspace: Precise LoRA Training Techniques
若你還不知道什麼是 Tensor.Art 或是不知道如何使用的話,歡迎先看看教學文章 Tensor Art 教學:目前最推薦的免費網頁版 AI 繪圖工具!
Tensor Art:https://tensor.art/
在我們推出了自己的 LoRA 模型線上培訓功能後,我們決定嘗試一下。(是的!我們終於推出了這個功能!如果您是專業培訓師,請點擊嘗試。)我們必須承認,雖然這個線上培訓該工具顯著簡化了流程,提供多種樣式和基礎模型可供選擇,創造出不僅高品質、而且滿足您滿意的 LoRA 結果,簡直就像在公園裡散步般簡單,它需要大量細緻的準備和深入研究細節。
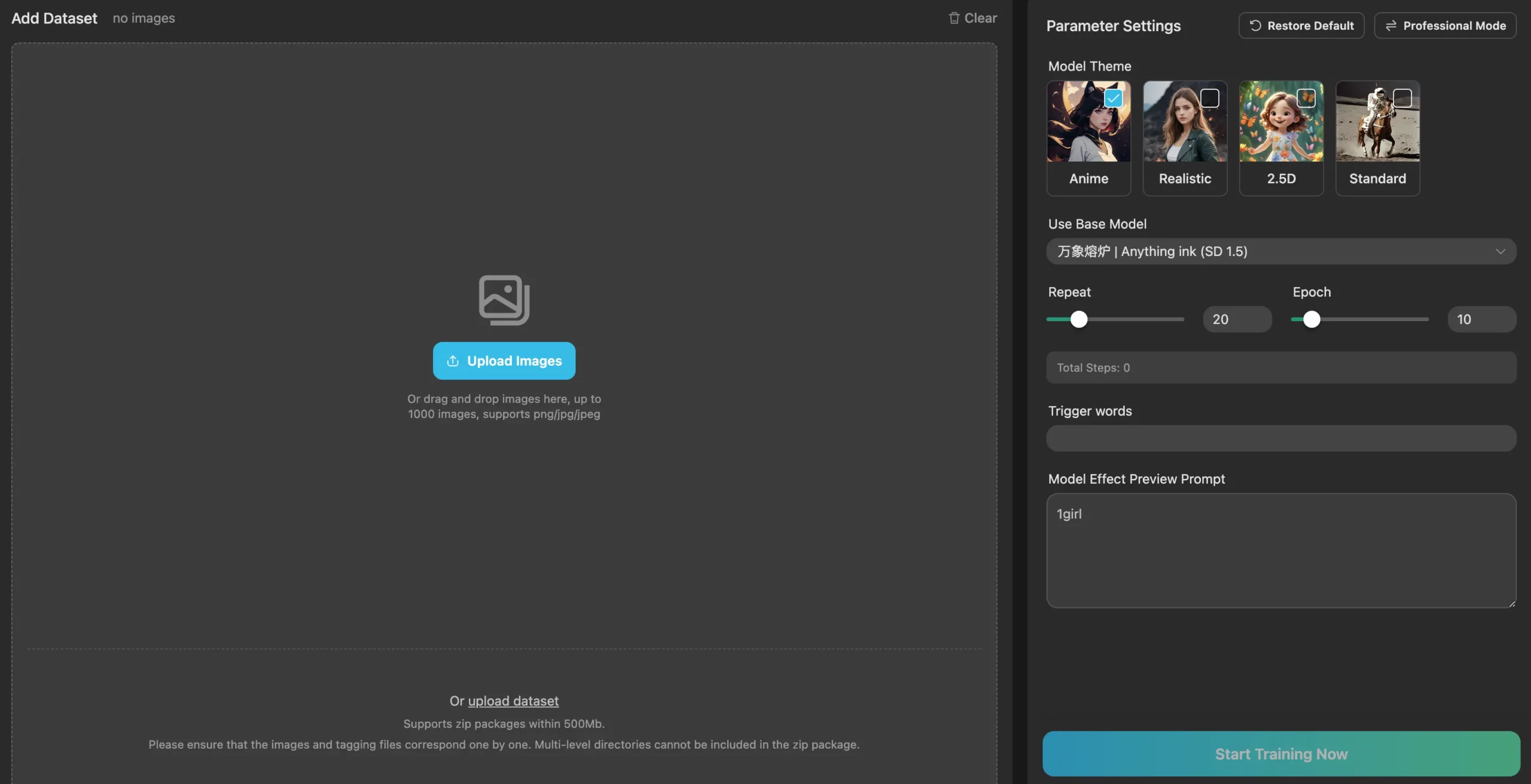
因此,在更深入了解 LoRA 訓練背後的原理後,我們確定了幫助您獲得更滿意的訓練結果的兩個關鍵因素:精確的訓練資料集和詳細的圖像標籤。
精確的訓練模型資料庫

明顯的共同主題
用於訓練的所有圖像都應具有明顯的共同主題。它們可以都是同一個角色的圖像,也可以都保持一致的風格,例如油畫或賽博龐克風格。清晰的培訓主題有助於 LoRA 培訓師集中注意力並更好地理解培訓集的內容。
高像素清晰度
為了幫助 LoRA 訓練者更輕鬆地理解和定義影像的細節,由於影像將在雜訊中分解,我們建議使用更高解析度的影像。例如,如果在訓練真實模型時使用高清人像圖像,則生成結果往往會具有更清晰的眼睛細節。相反,使用低解析度或模糊影像作為訓練資料可能會導致 LoRA 訓練器學習到「模糊」的感覺,從而使生成結果不那麼詳細。
相同主題/內容的多樣性
同一角色的不同姿勢和臉部表情可以為 LoRA 訓練者提供更廣泛的學習範圍,讓訓練結果在面對複雜的提示要求時產生更穩定的效果。
詳細的圖像標籤
首先,讓我們解釋一下標籤在資料庫中的工作原理:

您可以上傳帶有標籤的圖像,儘可能詳細。
→ LoRA 培訓師將參考標記的圖像,並根據您選擇的培訓基本模型模擬培訓結果。
→ 如果圖像中始終存在的元素不包含在標籤中,則它將被集成到 LoRA 中。 這是因爲 LoRA 旨在吸收那些難以用語言表達的細節。
了解這一點後,您就可以將如此複雜的細節封裝在啟動標籤(放置在每個文字檔案開頭的不同單字或短語)中,使您的 LoRA 易於提示。
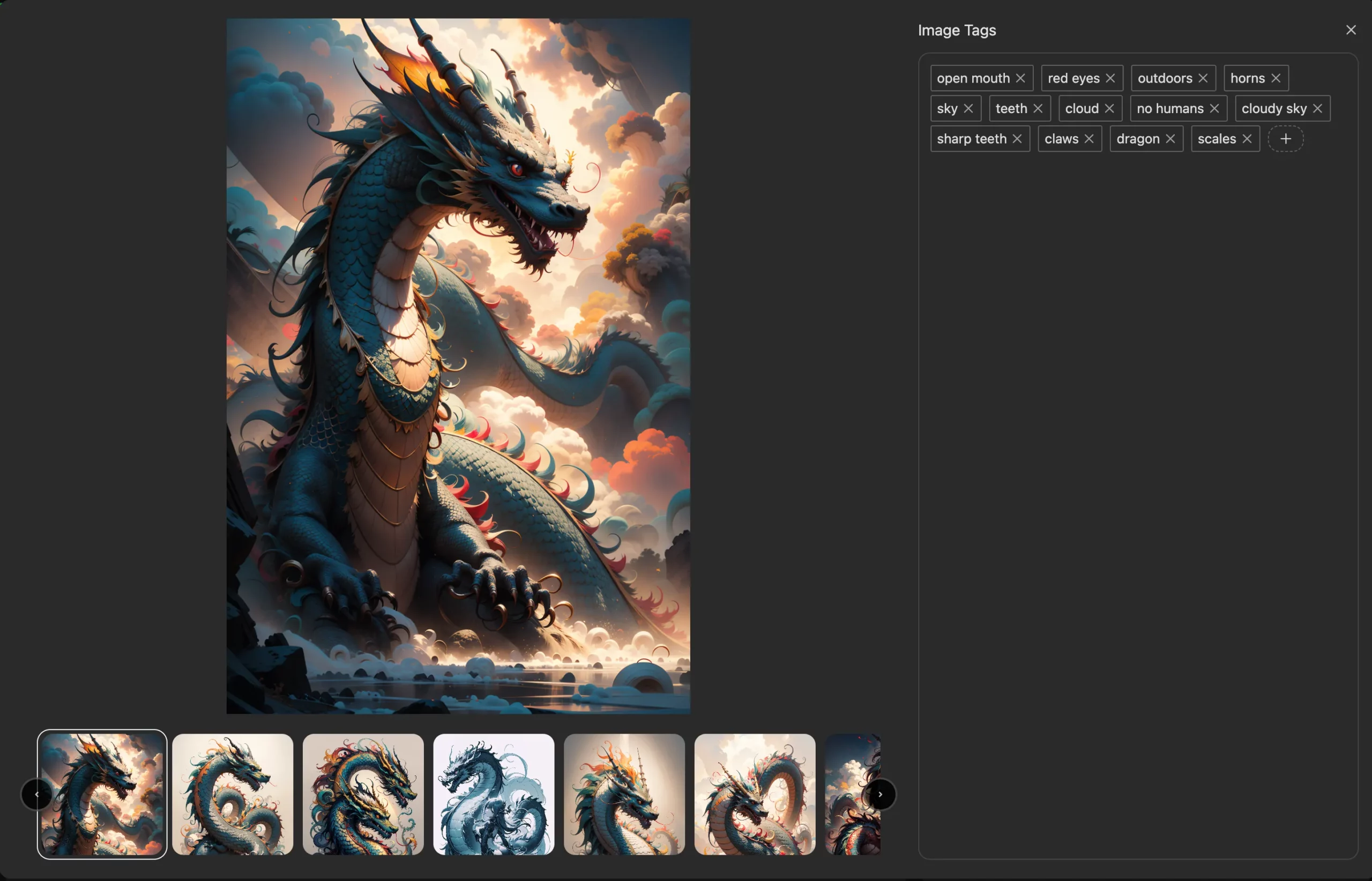
目前,我們提供兩種自動標籤選項,您可以在訓練介面的「自動標籤」部分找到它們。當然,您也可以在使用自動標籤後手動新增更多標籤,以補充更多內容。一般來說,幫助 LoRA 訓練器更好地學習和理解您的輸入訓練資料集將使其能夠更好地為您服務並輸出理想的訓練結果。
最後,我們想談談您肯定會使用的兩個訓練參數:
- 重複次數-這是指影像在訓練過程中重複的次數。 (例如,如果這個數字是 10,那麼每個圖像將重複 10 次:我的 28 個圖像的資料集變成 280 個圖像)
- Epochs — 機器學習中的「Epoch」是資料透過演算法的整輪訓練。 「Epochs」是由影像數量乘以其重複次數所決定的計數,全部除以批次大小。本質上,它是資料集訓練的總輪次。
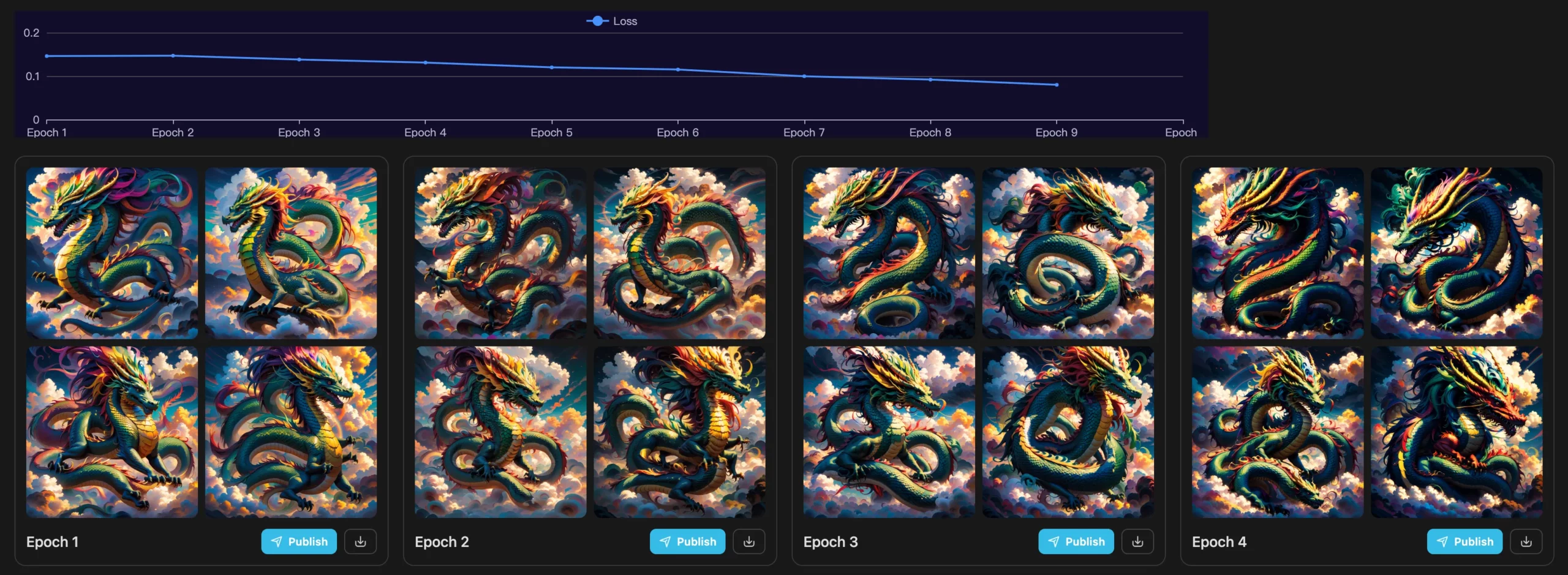
這裡需要提到的 Tensor.Art 線上訓練功能的另一個便利之處是我們提供了每個 epoch 效果的預覽。只需在訓練開始前輸入提示,訓練結束後即可獲得每個 epoch 的四張預覽影像。這樣您就可以快速選擇您想要的訓練結果!另外,您可以直接發布現有專案滿意的培訓結果,也可以下載並保存在你的電腦中!
現在是時候嘗試 Tensor.Art ,訓練自己的模型了!